Understanding Kernels, Work-groups and Work-items¶
In order to best structure your OpenCL code for fast execution, a clear understanding of OpenCL C kernels, work-groups, work-items, explicit iteration in kernels and the relationship between these concepts is imperative.
Additionally, knowing how these concepts map to an underlying hardware architecture is important, so that your application may be structured appropriately.
Knowledge of these concepts is not required in order to run an OpenCL application. OpenCL code is expression portable, meaning that a conformant OpenCL application should run correctly on any conformant OpenCL implementation. However, knowledge of these concepts is required in order to run an OpenCL application efficiently, i.e. OpenCL applications are not necessarily performance portable, and simple tweaks to the balance of explicit kernel iteration versus the number of work-items in a work-group can have a very large performance impact.
Enqueueing a Kernel¶
There are two OpenCL APIs for enqueueing a kernel.
- enqueueNDRangeKernel(), and
- enqueueTask().
enqueueTask is just a special case of enqueueNDRangeKernel where the offset, global size, and local size are fixed to 0, 1, and 1 respectively in a single dimension. This special case is very useful in many cases, but for the purposes of explaining the relationship of OpenCL C kernels, work-items and work-groups, this section will focus on the general API enqueueNDRangeKernel. This section will also assume the offset for the enqueueNDRangeKernel is 0 is all dimensions. The offset is useful in limited use cases relative to the global size and local size, and we refer you to the OpenCL 1.1 specification for more information on the use of offset.
The expression of an OpenCL C kernel is really an algorithm expression for one work-item. That one work-item expression is also associated with a kernel name. When an enqueueNDRangeKernel API call is made, the key three arguments to the API are :
- the kernel object which has previously been associated with the kernel name, and
- the number of work-items you wish to execute (called the global size), and
- the number of work-items you wish to group into a work-group (called the local size).
For example, the following C++ code
Q.enqueueNDRangeKernel(K, NullRange, NDRange(1024), NDRange(128));
Illustrates an enqueueNDRangeKernel command that will enqueue to the OpenCL queue named Q a kernel object named K.
The second argument is the offset and as previously stated we will assume it is 0 in all dimensions. The NullRange object will satisfy that 0 specification.
The third argument is the global size and it specifies a wish to execute 1024 instances of the work-item specified in the kernel source associated with the kernel object K.
The fourth argument is the local size and it specifies how many of the work-items should be grouped into a work-group. In this case, it is specified to be 128 work-items per work-group.
Since there are 1024 total work-items and 128 work-items / work-group, a simple division of 1024 / 128 = 8 work-groups.
- The global size (GSZ) is the total number of work-items (WI)
- The local size (LSZ) is the number of work-items per work-group (WI/WG)
- The number of work-groups is the global size / local size, or GSZ/LSZ, or WG
It is also possible for the global size and local size to be specified in 2 or 3 dimensions. For example a 2D kernel enqueue may look like
Q.enqueueNDRangeKernel(K, NullRange, NDRange(640, 480), NDRange(640, 1))
This enqueue specifies:
- A global size of 640 work-items in dimension 0 and 480 work-items in dimension 1, for a total of 640 * 480 = 307,200 total work-items (WI).
- It also specifies the local size to be 640 WI/WG in dimension 0 and 1 WI/WG in dimension 1.
- This results in 640/640 = 1 work-group in dimension 0 and 480/1 work-groups in dimension 1. for a total of 480 work-groups (WG)
Mapping the OpenCL C work-item Built-in Functions¶
OpenCL C contains eight built-in functions that can be used in the algorithmic expression of a kernel to query global size, local size, etc. Those eight functions are:
| Function | Property returned |
|---|---|
| uint get_work_dim() | The number of dimensions |
| size_t get_global_id(uint dimidx) | The ID of the current work-item [0,WI) in dimension dimidx |
| size_t get_global_size(uint dimidx) | The total number of work-items (WI) in dimension dimidx |
| size_t get_global_offset(uint dimidx) | The offset as specified in the enqueueNDRangeKernel API in dimension dimidx |
| size_t get_group_id(uint dimidx) | The ID of the current work-group [0, WG) in dimension dimidx |
| size_t get_local_id(uint dimidx) | The ID of the work-item within the work-group [0, WI/WG) in dimension dimidx |
| size_t get_local_size (uint dimidx) | The number of work-items per work-group = WI/WG in dimension dimidx |
| size_t get_num_groups(uint dimidx) | The total number of work-groups (WG) in dimension dimidx |
OpenCL C Kernel Code¶
The code in an OpenCL C kernel represents the algorithm to be applied to a single work-item. The granularity of a work item is determined by the implementer. If we take an element wise vector add example, where we take two 1 dimensional vectors as input, add them together element wise and write the result back into the first vector, we can express a kernel to achieve this behavior with either of the following
kernel vectorAdd(global int* A, global const int * B)
{
int gid = get_global_id(0);
A[gid] += B[gid];
}
Next example
#define ITER 16
kernel vectorAdd(global int* A, global const int * B)
{
int gid = get_global_id(0) * ITER;
int i;
for (i = 0; i < ITER; ++i)
{
A[gid + i] += B[gid+ i];
}
}
The first kernel will perform an add of one element of the input arrays per work-item and for arrays of length 1024, the enqueueNDRangeKernel call would need to specify 1024 as the global size. The second kernel will perform sixteen element adds per work-item and for the same 1024 length input arrays, the enqueueNDRangeKernel call would only need to specify a global size of 64, the 1024 elements / 16 elements per work-item.
NDRangeKernel Execution on DSP Devices¶
Number of Cores Available for NDRangeKernel Execution¶
The DSP devices in the Texas Instruments’ OpenCL implementation can be either a single core DSP or a multi core DSP with a varying number of cores. Either way, the grouping of all the DSP cores will be presented to the OpenCL developer as a single virtual DSP device with some number of compute units. The number of compute units will equate to the number of DSP cores available within the device.
To query the DSP device for the number of compute units (or cores), use the opencl device query capability. The following code illustrates how the host OpenCL application can determine the number of cores in a DSP device.
1 2 3 4 5 | Context context(CL_DEVICE_TYPE_ACCELERATOR);
std::vector<Device> devices = context.getInfo<CL_CONTEXT_DEVICES>();
int num;
devices[0].getInfo(CL_DEVICE_MAX_COMPUTE_UNITS, &num);
|
As described in a previous section, lines 1 and 2 will enumerate the number of DSP devices in the Texas Instruments’ OpenCL platform. On EVMs with embedded ARM + DSP devices, this will return 1 DSP device in devices[0]. On the Texas Instruments’ platform for the TMS320C6678 devices on a PCIe card, it will return 4 or 8 devices.
Line 5 assumes there is only the one device in devices[0] and it queries that device for the number of compute units, which will be set in the variable num in this example.
NDRangeKernel Work-Group Execution¶
The DSP cores (compute units) within the virtual DSP device behave like a heterogeneous thread pool for work-groups that are created by an enqueueNDRangeKernel call on the host. Each DSP core will pull a work-group off the work-group queue (like a thread pool queue). It will execute the work-group to completion and will then pull another work-group from the queue. This will continue untill all the work-groups for an NDRangeKernel submission are complete.
The Figure below illustrates an in-flight execution of an NDRangeKernel with 8 work-groups executing on a 4-core DSP. The green boxes represent the DSP cores. The circles represent the work-groups. Blue work-groups are waiting to be executed, pink work-groups are currently executing and yellow work-groups have been completed.
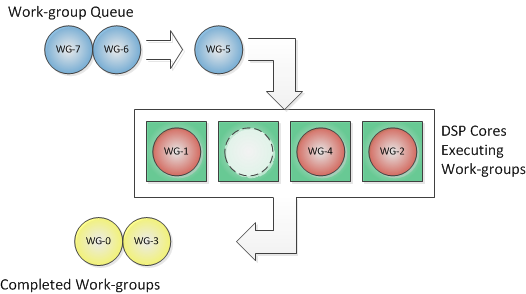
In this example, work-groups 0 and 3 have been completed, work-groups 1, 2 and 4 are currently executing, work-groups 6 and 7 are waiting, and work-group 5 has just been selected from the waiting queue and is about to be assigned to the idle core 1 for execution.
After all 8 work-groups have completed, the NDRangeKernel submission is deemed to have completed and any OpenCL event associated with the enqueueNDRangeKernel will have its status updated to CL_COMPLETE. A wait operation on an event will be satisfied once the event status is updated to CL_COMPLETE, and the thread will be allowed to progress.
The above figure could have resulted from code similar to the following:
1 2 3 4 5 | Event ev;
Q.enqueueNDRangeKernel(K, NullRange, NDRange(8), NDRange(1), NULL, &ev);
concurrent();
ev.wait()
post();
|
In this example code, an OpenCL Queue named Q and a Kernel named K already exist. Line 1 defines an OpenCL event object ev. Line 2 enqueues kernel K to queue Q with a global size of 8 and a local size of 1, resulting in a total of 8 work-groups. The fifth argument is a vector of events that must be completed before this submission of kernel K may begin. In this example, that set of dependencies is NULL. The sixth argument is the address of an event to associate with this kernel submission, which is ev defined in line 1.
When the enqueue command on line 2 executes, it will place this kernel submission in the OpenCL command-queue Q. The enqueue command will then return and line 3 of the example, the call to concurrent can begin to execute.
Asynchronously, the OpenCL runtime is monitoring the command-queue Q for kernel submissions where all dependencies for the kernel are satisfied. When the runtime identifies one, it will create the appropriate number of work-groups for the kernel and will place them in the work-group queue for the device associated with Q. In this example, there were no dependencies for kernel K, so the runtime will perform this task immediately, assuming the device is available.
At this point in time, the host CPU is executing the function concurrent and the DSP cores are concurrently executing the work-groups for the kernel K. Lets assume that the host function concurrent completes first, thus allowing the thread to continue to line 4 where a wait operation is executed on the OpenCL event associated with the submission of kernel K. The wait operation will block the thread until the status of the event is CL_COMPLETE.
The OpenCL runtime will update the status of ev to CL_COMPLETE after all 8 work-groups for kernel K have been completed. When this occurs, the wait operation on line 4 will be satisfied and the thread will continue to line 5 where the host executes the function post.
Note
The work-groups for an NDRangeKernel submission can be started in any order, they can be completed in any order and they can be assigned to any core on the device.
NDRangeKernel Work-Item within a Work-Group Execution¶
In an OpenCL application, the body of a kernel function expresses the computation to be completed for a single work-item. The number of work-items to compute is specified in the enqueueNDRangeKernel command for the kernel as the global size argument. The local size argument defines how many work-items are grouped within a single work-group. The previous section described the execution of work-groups. This section will describe how work-items within a work-group execute.
OpenCL implementations may vary significantly in the details of how work-items are executed within a work-group. That variability will be based on the hardware architecture of the device on which the work-items are executing. For GPUs with wide SIMD (Single Instruction Multiple Data) architectures, some number of work-items within a work-group will execute concurrently, one work-item per SIMD lane of the architecture. On Texas Instruments’ DSPs, which are inherently iterative in nature, the work-items within a work-group will execute sequentially.
In order for the work-items to execute sequentially in an efficient manner, the OpenCL C compiler in the Texas Instruments’ OpenCL implementation will create loops around the body of a kernel function. For example, in the below example code, the function vectorAdd is an example of kernel expressing the computation for a single work-item. It queries the global work-item ID using the function get_global_id. It then uses the ID to index into the A and B arrays, and adds the B element to the A element.
kernel vectorAdd(global int* A, global const int * B)
{
int gid = get_global_id(0);
A[gid] += B[gid];
}
During compilation by the TI OpenCL C compiler, the above kernel expression is transformed into code to represent an entire work-group. The transformation would make the above code look like the below code.
extern uint32_t _local_size[3];
extern uint32_t _first_gid_in_wg[3];
kernel vectorAdd(global int* A, global const int * B)
{
int _local_id_0;
for (_local_id_0 = 0; _local_id_0 < _local_size[0]; _local_id_0++)
{
int gid = _local_id_0 + _first_gid_in_wg[0];
A[gid] += B[gid];
}
}
The external variables _local_size and _first_gid_in_wg are arrays of three elements, one for each potential dimension of an NDRangeKernel. The OpenCL runtime will populate these variables based on the arguments to the enqueueNDRangeKernel command in the host application.
The above example kernel only expressed 1 dimension of access and so the transformed kernel had 1 level of loop inserted. For kernels with two or three dimensional access the compiler would transform the kernel to include two or three levels of loops, respectively.
NDRangeKernels: Putting it All Together¶
From the previous sections, we have shown that:
- Kernels as expressed in source, represent the computation for 1 work-item,
- The local size specified in the enqueueNDRangeKernel command determines how many work-items are grouped into a single work-group,
- On TI DSP devices, work-items within a work-group execute sequentially via compiler inserted loops,
- The global size specified in the enqueueNDRangeKernel command determines how many total work-items there are, and also how many work-groups there are by dividing global size by local size,
- On TI DSP devices, work-groups are executed concurrently across DSP cores in work pool fashion until all work-groups for an enqueue command are completed,
- The number of work-groups that can concurrently execute is determined by the number of DSP cores in the device (in OpenCL terms a DSP core is a compute unit).
The below figure visually summarizes the above by showing two enqueueNDRangeKernel commands that would semantically perform the same total computation, but by simply changing the local size argument, the balance of how the kernel is executed is changed. In both cases the global size is 1024. In case 1, the local size is 128 and this results in an execution partition that creates 8 work-groups, each of which will iterate through 128 work-items. In case 2, the local size is changed to 256 and this results in 4 work-groups, each with 256 work-items.
