Using the API¶
This section illustrates using TIDL APIs to leverage deep learning in user applications. The overall flow is as follows:
- Create a Configuration object to specify the set of parameters required for network exectution.
- Create Executor objects - one to manage overall execution on the EVEs, the other for C66x DSPs.
- Use the Execution Objects (EO) created by the Executor to process frames. There are two approaches to processing frames using Execution Objects:
| Use Case | Application/Network characteristic | Examples |
|---|---|---|
| Each EO processes a single frame. The network consists of a single Layer Group and the entire Layer Group is processed on a single EO. See Each EO processes a single frame. | one_eo_per_frame, imagenet, segmentation | |
| Split processing a single frame across multiple EOs using an ExecutionObjectPipeline. The network consists of 2 or more Layer Groups. See Frame split across EOs and Using EOPs for double buffering. |
|
two_eo_per_frame, two_eo_per_frame_opt, ssd_multibox |
Refer Section API Reference for API documentation.
Use Cases¶
Each EO processes a single frame¶
In this approach, the network is set up as a single Layer Group. An EO runs the entire layer group on a single frame. To increase throughput, frame processing can be pipelined across available EOs. For example, on AM5749, frames can be processed by 4 EOs: one each on EVE1, EVE2, DSP1, and DSP2.
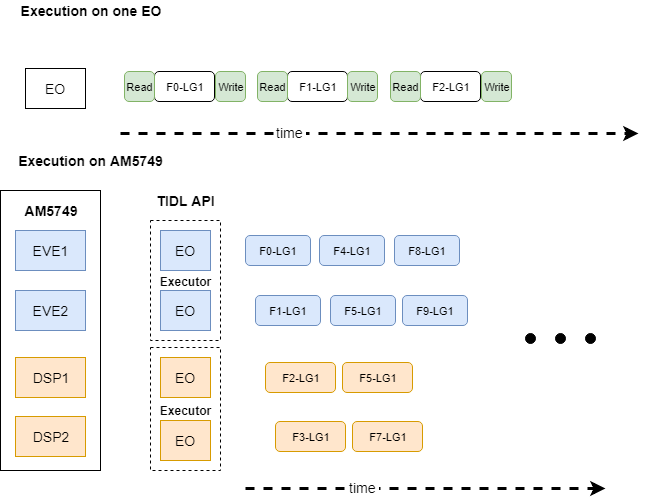
Fig. 3 Processing a frame with one EO. Not to scale. Fn: Frame n, LG: Layer Group.
Determine if there are any TIDL capable compute cores on the AM57x Processor:
1 2
uint32_t num_eve = Executor::GetNumDevices(DeviceType::EVE); uint32_t num_dsp = Executor::GetNumDevices(DeviceType::DSP);
Create a Configuration object by reading it from a file or by initializing it directly. The example below parses a configuration file and initializes the Configuration object. See
examples/test/testvecs/config/inferfor examples of configuration files.1 2 3
Configuration c; if (!c.ReadFromFile(config_file)) return false;
Create Executor on C66x and EVE. In this example, all available C66x and EVE cores are used (lines 2-3 and CreateExecutor).
Create a vector of available ExecutionObjects from both Executors (lines 7-8 and CollectEOs).
Allocate input and output buffers for each ExecutionObject (AllocateMemory)
Run the network on each input frame. The frames are processed with available execution objects in a pipelined manner. The additional num_eos iterations are required to flush the pipeline (lines 15-26).
- Wait for the EO to finish processing. If the EO is not processing a frame (the first iteration on each EO), the call to
ProcessFrameWaitreturns false.ReportTimeis used to report host and device execution times. - Read a frame and start running the network.
ProcessFrameStartAsyncis asynchronous and returns before processing is complete.ReadFrameis application specific and used to read an input frame for processing. For example, with OpenCV,ReadFrameis implemented using OpenCV APIs to capture a frame from the camera.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
// Create Executors - use all the DSP and EVE cores available unique_ptr<Executor> e_dsp(CreateExecutor(DeviceType::DSP, num_dsp, c)); unique_ptr<Executor> e_eve(CreateExecutor(DeviceType::EVE, num_eve, c)); // Accumulate all the EOs from across the Executors vector<ExecutionObject *> EOs; CollectEOs(e_eve.get(), EOs); CollectEOs(e_dsp.get(), EOs); AllocateMemory(EOs); // Process frames with EOs in a pipelined manner // additional num_eos iterations to flush the pipeline (epilogue) int num_eos = EOs.size(); for (int frame_idx = 0; frame_idx < c.numFrames + num_eos; frame_idx++) { ExecutionObject* eo = EOs[frame_idx % num_eos]; // Wait for previous frame on the same eo to finish processing if (eo->ProcessFrameWait()) ReportTime(eo); // Read a frame and start processing it with current eo if (ReadFrame(eo, frame_idx, c, input_data_file)) eo->ProcessFrameStartAsync(); }
1 2 3 4 5 6 7 8 9 10
Executor* CreateExecutor(DeviceType dt, int num, const Configuration& c) { if (num == 0) return nullptr; DeviceIds ids; for (int i = 0; i < num; i++) ids.insert(static_cast<DeviceId>(i)); return new Executor(dt, ids, c); }
1 2 3 4 5 6 7
void CollectEOs(const Executor *e, vector<ExecutionObject *>& EOs) { if (!e) return; for (unsigned int i = 0; i < e->GetNumExecutionObjects(); i++) EOs.push_back((*e)[i]); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
void AllocateMemory(const vector<ExecutionObject *>& eos) { // Allocate input and output buffers for each execution object for (auto eo : eos) { size_t in_size = eo->GetInputBufferSizeInBytes(); size_t out_size = eo->GetOutputBufferSizeInBytes(); void* in_ptr = malloc(in_size); void* out_ptr = malloc(out_size); assert(in_ptr != nullptr && out_ptr != nullptr); ArgInfo in = { ArgInfo(in_ptr, in_size)}; ArgInfo out = { ArgInfo(out_ptr, out_size)}; eo->SetInputOutputBuffer(in, out); } }
- Wait for the EO to finish processing. If the EO is not processing a frame (the first iteration on each EO), the call to
The complete example is available at /usr/share/ti/tidl/examples/one_eo_per_frame/main.cpp.
Note
The double buffering technique described in Using EOPs for double buffering can be used with a single ExecutionObject to overlap reading an input frame with the processing of the previous input frame. Refer to examples/imagenet/main.cpp.
Frame split across EOs¶
This approach is typically used to reduce the latency of processing a single frame. Certain network layers such as Softmax and Pooling run faster on the C66x vs. EVE. Running these layers on C66x can lower the per-frame latency.
Time to process a single frame 224x224x3 frame on AM574x IDK EVM (Arm @ 1GHz, C66x @ 0.75GHz, EVE @ 0.65GHz) with JacintoNet11 (tidl_net_imagenet_jacintonet11v2.bin), TIDL API v1.1:
| EVE | C66x | EVE + C66x |
|---|---|---|
| ~112ms | ~120ms | ~64ms 1 |
1 BatchNorm and Convolution layers run on EVE are placed in a Layer Group and run on EVE. Pooling, InnerProduct, SoftMax layers are placed in a second Layer Group and run on C66x. The EVE layer group takes ~57.5ms, C66x layer group takes ~6.5ms.
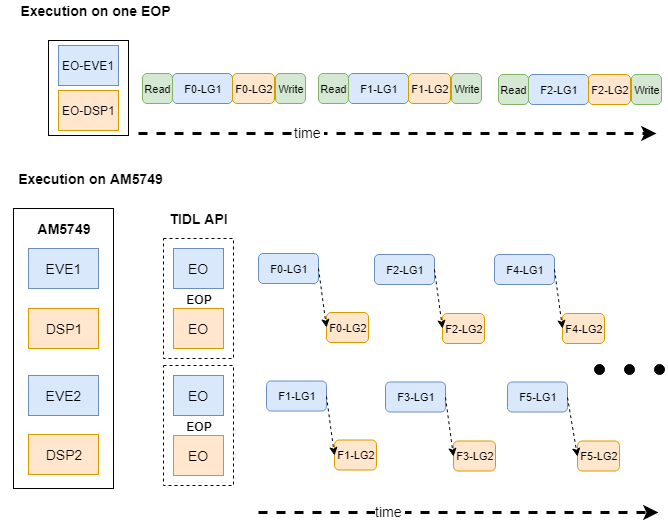
Fig. 4 Processing a frame across EOs. Not to scale. Fn: Frame n, LG: Layer Group.
The network consists of 2 Layer Groups. Execution Objects are organized into Execution Object Pipelines (EOP). Each EOP processes a frame. The API manages inter-EO synchronization.
Determine if there are any TIDL capable compute cores on the AM57x Processor:
1 2
uint32_t num_eve = Executor::GetNumDevices(DeviceType::EVE); uint32_t num_dsp = Executor::GetNumDevices(DeviceType::DSP);
Create a Configuration object by reading it from a file or by initializing it directly. The example below parses a configuration file and initializes the Configuration object. See
examples/test/testvecs/config/inferfor examples of configuration files.1 2 3
Configuration c; if (!c.ReadFromFile(config_file)) return false;
Update the default layer group index assignment. Pooling (layer 12), InnerProduct (layer 13) and SoftMax (layer 14) are added to a second layer group. Refer Overriding layer group assignment for details.
1 2
const int DSP_LG = 2; c.layerIndex2LayerGroupId = { {12, DSP_LG}, {13, DSP_LG}, {14, DSP_LG} };
Create Executors on C66x and EVE. The EVE Executor runs layer group 1, the C66x executor runs layer group 2.
Create two Execution Object Pipelines. Each EOP contains one EVE and one C66x Execution Object respectively.
Allocate input and output buffers for each ExecutionObject in the EOP. (AllocateMemory)
Run the network on each input frame. The frames are processed with available EOPs in a pipelined manner. For ease of use, EOP and EO present the same interface to the user.
- Wait for the EOP to finish processing. If the EOP is not processing a frame (the first iteration on each EOP), the call to
ProcessFrameWaitreturns false.ReportTimeis used to report host and device execution times. - Read a frame and start running the network.
ProcessFrameStartAsyncis asynchronous and returns before processing is complete.ReadFrameis application specific and used to read an input frame for processing. For example, with OpenCV,ReadFrameis implemented using OpenCV APIs to capture a frame from the camera.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
int num_eops = EOPs.size(); for (int frame_idx = 0; frame_idx < c.numFrames + num_eops; frame_idx++) { EOP* eop = EOPs[frame_idx % num_eops]; // Wait for previous frame on the same EOP to finish processing if (eop->ProcessFrameWait()) { } // Read a frame and start processing it with current eo if (ReadFrame(eop, frame_idx, c, input)) eop->ProcessFrameStartAsync(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
void AllocateMemory(const vector<ExecutionObjectPipeline *>& eops) { // Allocate input and output buffers for each execution object for (auto eop : eops) { size_t in_size = eop->GetInputBufferSizeInBytes(); size_t out_size = eop->GetOutputBufferSizeInBytes(); void* in_ptr = malloc(in_size); void* out_ptr = malloc(out_size); assert(in_ptr != nullptr && out_ptr != nullptr); ArgInfo in = { ArgInfo(in_ptr, in_size)}; ArgInfo out = { ArgInfo(out_ptr, out_size)}; eop->SetInputOutputBuffer(in, out); } }
- Wait for the EOP to finish processing. If the EOP is not processing a frame (the first iteration on each EOP), the call to
The complete example is available at /usr/share/ti/tidl/examples/two_eo_per_frame/main.cpp. Another example of using the EOP is SSD.
Using EOPs for double buffering¶
The timeline shown in Fig. 4 indicates that EO-EVE1 waits for processing on E0-DSP1 to complete before it starts processing its next frame. It is possible to optimize the example further and overlap processing F n-2 on EO-DSP1 and F n on E0-EVE1. This is illustrated in Fig. 5.

Fig. 5 Optimizing using double buffered EOPs. Not to scale. Fn: Frame n, LG: Layer Group.
EOP1 and EOP2 use the same EOs: E0-EVE1 and E0-DSP1. Each EOP has it’s own input and output buffer. This enables EOP2 to read an input frame when EOP1 is processing its input frame. This in turn enables EOP2 to start processing on EO-EVE1 as soon as EOP1 completes processing on E0-EVE1.
The only change in the code compared to Frame split across EOs is to create an additional set of EOPs for double buffering:
1 2 3 4 5 6 7 8 9 10 11 12 13 | // On AM5749, create a total of 4 pipelines (EOPs):
// EOPs[0] : { EVE1, DSP1 }
// EOPs[1] : { EVE1, DSP1 } for double buffering
// EOPs[2] : { EVE2, DSP2 }
// EOPs[3] : { EVE2, DSP2 } for double buffering
const uint32_t pipeline_depth = 2; // 2 EOs in EOP => depth 2
std::vector<EOP *> EOPs;
uint32_t num_pipe = std::max(num_eve, num_dsp);
for (uint32_t i = 0; i < num_pipe; i++)
for (uint32_t j = 0; j < pipeline_depth; j++)
EOPs.push_back(new EOP( { (*eve)[i % num_eve],
(*dsp)[i % num_dsp] } ));
|
Note
EOP1 in Fig. 5 -> EOPs[0] in Listing 5.
EOP2 in Fig. 5 -> EOPs[1] in Listing 5.
The complete example is available at /usr/share/ti/tidl/examples/two_eo_per_frame_opt/main.cpp.
Sizing device side heaps¶
TIDL API allocates 2 heaps for device size allocations during network setup/initialization:
| Heap Name | Configuration parameter | Default size |
| Parameter | Configuration::PARAM_HEAP_SIZE | 9MB, 1 per Executor |
| Network | Configuration::NETWORK_HEAP_SIZE | 64MB, 1 per ExecutionObject |
Depending on the network being deployed, these defaults may be smaller or larger than required. In order to determine the exact sizes for the heaps, the following approach can be used:
Start with the default heap sizes. The API displays heap usage statistics when Configuration::showHeapStats is set to true.
Configuration configuration;
bool status = configuration.ReadFromFile(config_file);
configuration.showHeapStats = true;
If the heap size is larger than required by device side allocations, the API displays usage statistics. When Free > 0, the heaps are larger than required.
# ./test_tidl -n 1 -t e -c testvecs/config/infer/tidl_config_j11_v2.txt
API Version: 01.01.00.00.e4e45c8
[eve 0] TIDL Device Trace: PARAM heap: Size 9437184, Free 6556180, Total requested 2881004
[eve 0] TIDL Device Trace: NETWORK heap: Size 67108864, Free 47047680, Total requested 20061184
Update the application to set the heap sizes to the “Total requested size” displayed:
configuration.PARAM_HEAP_SIZE = 2881004;
configuration.NETWORK_HEAP_SIZE = 20061184;
# ./test_tidl -n 1 -t e -c testvecs/config/infer/tidl_config_j11_v2.txt
API Version: 01.01.00.00.e4e45c8
[eve 0] TIDL Device Trace: PARAM heap: Size 2881004, Free 0, Total requested 2881004
[eve 0] TIDL Device Trace: NETWORK heap: Size 20061184, Free 0, Total requested 20061184
Now, the heaps are sized as required by network execution (i.e. Free is 0)
and the configuration.showHeapStats = true line can be removed.
Note
If the default heap sizes are smaller than required, the device will report an allocation failure and indicate the required minimum size. E.g.
# ./test_tidl -n 1 -t e -c testvecs/config/infer/tidl_config_j11_v2.txt
API Version: 01.01.00.00.0ba86d4
[eve 0] TIDL Device Error: Allocation failure with NETWORK heap, request size 161472, avail 102512
[eve 0] TIDL Device Error: Network heap must be >= 20061184 bytes, 19960944 not sufficient. Update Configuration::NETWORK_HEAP_SIZE
TIDL Error: [src/execution_object.cpp, Wait, 548]: Allocation failed on device
Note
The memory for parameter and network heaps is itself allocated from OpenCL global memory (CMEM). Refer Insufficient OpenCL global memory for details.
In addition, the following environment variables are provided to overwrite the heap sizes and heap allocation optimization level (1 or 2) that are specified by default or by application.
TIDL_PARAM_HEAP_SIZE_EVE
TIDL_PARAM_HEAP_SIZE_DSP
TIDL_NETWORK_HEAP_SIZE_EVE
TIDL_NETWORK_HEAP_SIZE_DSP
TIDL_EXTMEM_ALLOC_OPT_EVE
TIDL_EXTMEM_ALLOC_OPT_DSP
# # for example,
# TIDL_PARAM_HEAP_SIZE_EVE=3000000 TIDL_NETWORK_HEAP_SIZE_EVE=21000000 TIDL_PARAM_HEAP_SIZE_DSP=3000000 TIDL_NETWORK_HEAP_SIZE_DSP=2000000 ./tidl_classification -g 2 -d 1 -e 4 -l ./imagenet.txt -s ./classlist.txt -i ./clips/test10.mp4 -c ./stream_config_j11_v2.txt
Accessing outputs of network layers¶
TIDL API v1.1 and higher provides the following APIs to access the output buffers associated with network layers:
ExecutionObject::WriteLayerOutputsToFile- write outputs from each layer into individual files. Files are named<filename_prefix>_<layer_index>.bin.ExecutionObject::GetOutputsFromAllLayers- Get output buffers from all layers.ExecutionObject::GetOutputFromLayer- Get a single output buffer from a layer.
See examples/layer_output/main.cpp, ProcessTrace() for examples of using these tracing APIs.
Note
The ExecutionObject::GetOutputsFromAllLayers method can be memory intensive if the network has a large number of layers. This method allocates sufficient host memory to hold all output buffers from all layers.